向后兼容
1 如果一列的值都为空,那么COUNT(DISTINCT)统计出来的值为0,不再是NULL

2 增加了对用户在配置文件中的自定义配置项的检查
3 input_format_with_names_use_header默认开启. 它将影响使用-WithNames 和-WithNamesAndTypes 格式进行数据的导入。
4 删除了experimental_use_processors的设置,默认开启。
5 将zstd更新到1.4.4版本,这对这个版本的数据在性能和压缩率上有轻微的影响。如果你的数据副本位于不同版本的Clickhouse上,可能会遇到Data after merge is not byte-identical to data on another replicas.这样的错误信息,不要为此担心,我们做了向后兼容,之所以在这里提到此事,为了让你知道为什么会遇到此信息。
6 增加了对无效压缩编码设置的检查,allow_suspicious_codecs可以控制这个检查。
7 一些kafka连接设置调整。参考官网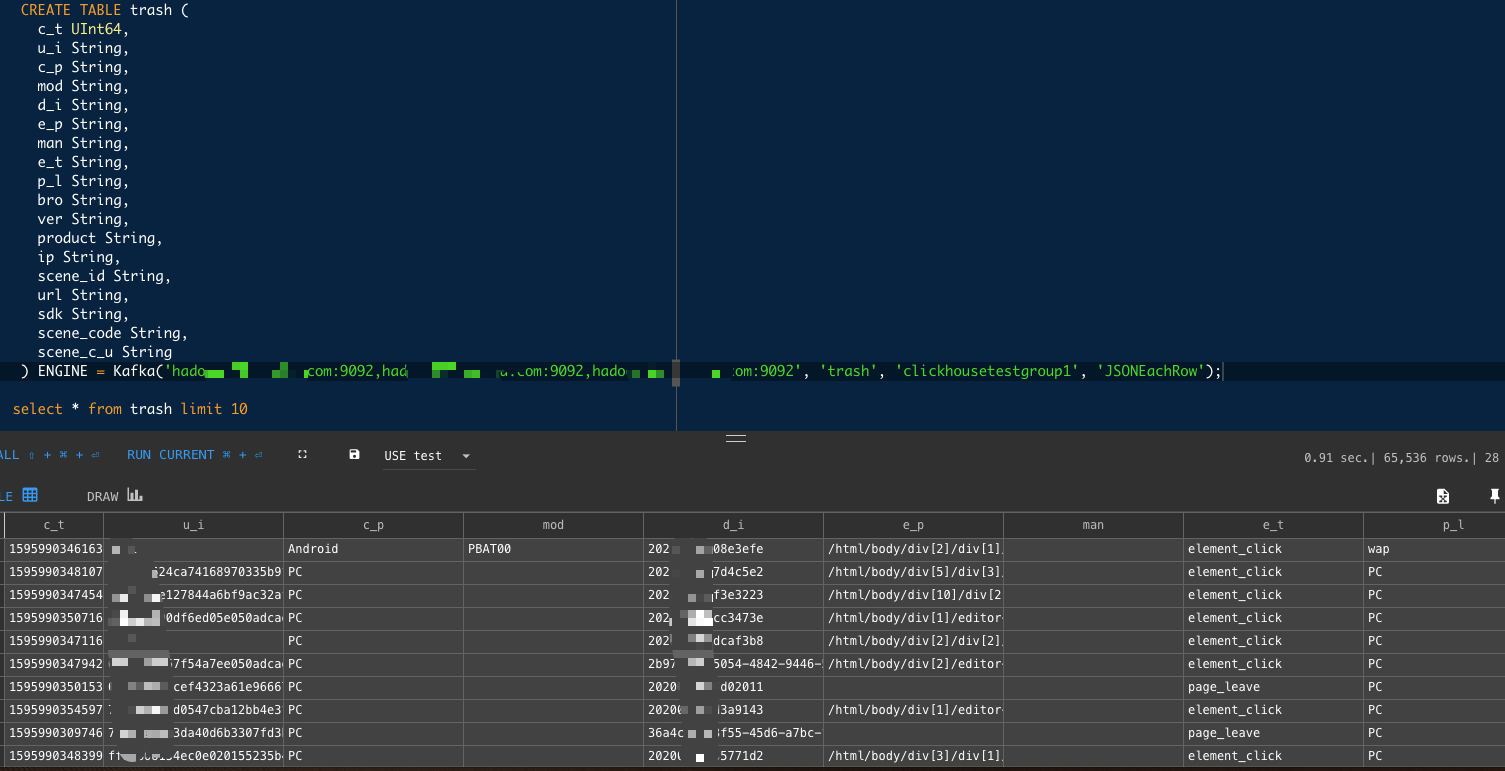
一些重要的新特性
1 TTL DELETE WHERE 和 TTL GROUP BY 用于自动进行数据域的汇总。
根据条件删除过期的数据1
2
3
4
5
6
7
8CREATE TABLE example_table
(
d DateTime, a Int
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(d)
ORDER BY d
TTL d + INTERVAL 1 MONTH DELETE WHERE cityHash(a) % 10 = 0;
根据设置的过期时间聚合数据1
2
3
4
5
6
7CREATE TABLE example_table
(
d DateTime, k1 Int, k2 Int, x Int, y Int
)
ENGINE = MergeTree
ORDER BY k1, k2
TTL d + INTERVAL 1 MONTH GROUP BY k1, k2 SET x = sum(x), y = min(y);
2 增加一些系统表,比如users, roles, grants, settings profiles, quotas, row policies。 增加一些命令:SHOW USER, SHOW [CURRENT|ENABLED] ROLES, SHOW SETTINGS PROFILES.
3 增加基于Linux perf_events的查询性能指标,不过它是可选的,并且需要对CAP_SYS_ADMIN进行设置。
4 在创建表的时候可以为数据类型指定NULL或NOT NULL修饰符。
5 为kafka引擎的数据增加2个虚拟列。
6 支持Cassandra作为外部字典。
7 增加了一个新的字典类型direct,这类的字典数据在每次查询的时候直接从数据源加载数据,但是并不存储在Clickhouse或缓存到内存中。
8 增加了对MySQL风格的全局变量语法支持
9 clickhouse-client语法高亮显示
10 增加了minMap 和 maxMap 函数


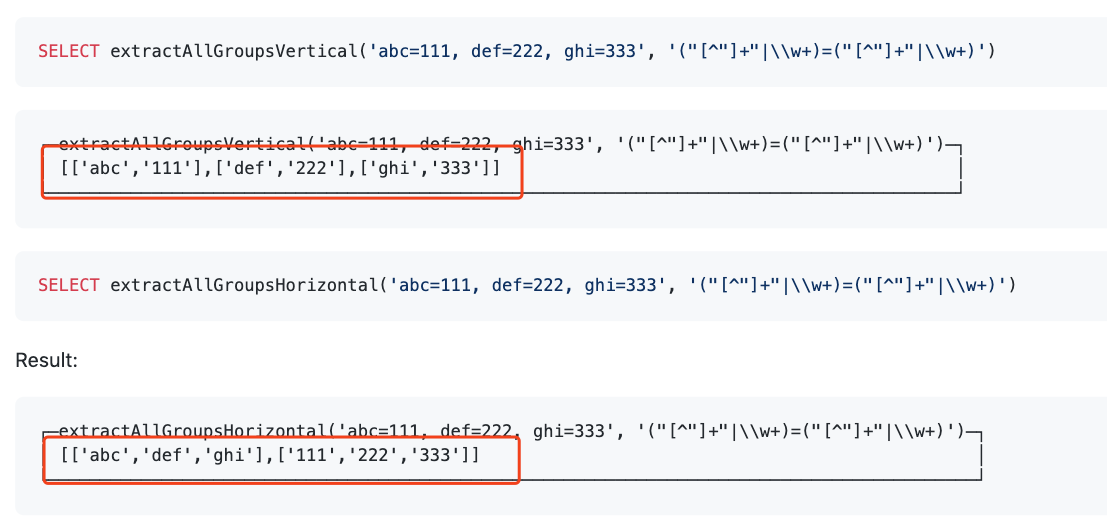
11 增加extractAllGroupsHorizontal(haystack, re)和extractAllGroupsVertical(haystack, re)函数,可以从字符串中使用正则表达式抽取一系列的值。
12 增加SHOW CLUSTER(S) 查询命令
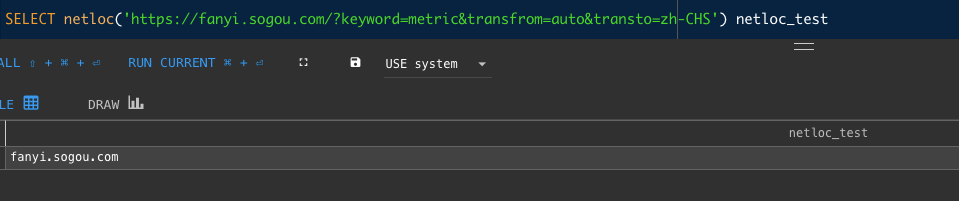
13 增加netloc函数,用来从网络地址中抽取信息,类似于Python中的urlparse(url)
14 为kafka引擎的数据增加 _timestamp_ms 虚拟字段,类型为Nullable(DateTime64(3))
15 增加randomFixedString函数,生成固定长度的随机字符串。
16 允许数字和字符串常量的比较操作
17 增加round_robin的负载均衡策略
18 增加cast_keep_nullable设置,如果使用CAST(something_nullable AS Type),返回的则是Nullable(Type)类型
19 在system.columns表中增加了column列,在system.parts_columns表中增加了column_position列。

20 集群支持SYSTEM {FLUSH DISTRIBUTED,STOP/START DISTRIBUTED SEND}操作
21 增加system.distribution_queue表
22 对kafka数据源更好的支持,参考https://github.com/ClickHouse/ClickHouse/pull/11388
23 增加port函数,抽取URL中的端口号
24 dictGet*类的函数接受表名作为参数
25 当使用-n参数的时候,clickhouse-format工具可以同时格式化多个查询。
26 NCHAR 和 NVARCHAR 类型支持
27 在表增加system.events中增加FailedQuery, FailedSelectQuery 和 FailedInsertQuery度量
28 允许指定默认S3证书和自定义的授权信息
29 增加新函数用来将DateTime64导入或导出为各种精度的Int64类型的值:to-/fromUnixTimestamp64Milli/-Micro/-Nano
30 允许指定mongodb://URI作为字典
31 OFFSET关键字可以单独使用,而不必非得加LIMIT
32 增加system.licenses表,这个表中包含了第三方依赖的一些licenses
33 新函数为startofsecond(DateTime64)-> datetime 64,它使DateTime64的次秒部分无效
34 增加JSONAsString输入类型支持,JSONAsString接收换行符,空格或逗号分隔的一系列的JSON对象。
35 SimpleAggregateFunction 现在也支持 sumMap 了
36 分布式表支持ALTER RENAME COLUMN特性
37 允许以比4 MiB更细的粒度级来配置内存。添加了采样内存分析器来捕获随机内存分配/内存回收。