向后兼容变化
- 改变了SQL/JSON函数中json_path和json参数的位置。
- 移除了MergeTree表的write_final_mark设置,这个值总是为true,新的版本会兼容所有的表,不需要其他的设置。
- 移除了bayesAB函数。
- 如果你已经开始使用clickhouse-keeper 特性,可以看一下这条内容。现在ClickHouse Keeper快照默认使用ZSTD编码的方式进行压缩,而不再是LZ4块压缩,可以通过compress_snapshots_with_zstd_format 设置来关闭此特性(在所有的集群副本上保持设置一致)。一般都是向后兼容的,但是也有可能出现不兼容的情况,当一个新节点向不能读取ZSTD格式快照的旧节点发送快照的时候(在恢复的时候可能会发生)。
新特性
- 新的异步的insert模式允许在后台累积insert的数据并将它们放到一个批次中。在客户端可以通过对async_insert 设置为内联的INSERT语句启用这个设置(针对通过HTTP协议的INSERT语句)。如果wait_for_async_insert 设置为true(默认情况下为true),客户端会一直等到数据被刷写到表中。在服务器端,通过async_insert_threads, async_insert_max_data_size and async_insert_busy_timeout_ms设置来控制。注意一下性能问题,异步写入可以达到10000条每秒,所以如果你想实现每秒百万行的写入,推荐使用批量写入的方式。
- 为clickhouse-local增加交互模式。所以,你可以启动clickhouse-local 命令行Clickhouse界面,来处理文件数据,或者其他数据源的数据,而不需要连接服务器。将clickhouse-client 和 clickhouse-local 的代码合并在了一起。参考https://clickhouse.com/docs/zh/operations/utilities/clickhouse-local/
准备一些文件数据
1
2
3
4
5
6
7
8
9
10# clickhouse-local -N test_table --file='/data/test/ad_name_fixed1.csv' --input-format=CSV -S "id String, ad_ori_name String, ad_now_name String " -q "SELECT * from test_table limit 10 FORMAT Pretty"
┏━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ id ┃ ad_ori_name ┃ ad_now_name ┃
┡━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ 5492 │ pc端_互动/互动/转盘抽奖-模板 │ pc端_互动/互动/转盘抽奖-模板 │
├──────┼──────────────────────────────┼──────────────────────────────┤
│ 5493 │ pc端_互动/互动/招生-大转盘 │ pc端_互动/互动/招生-大转盘 │
├──────┼──────────────────────────────┼──────────────────────────────┤
│ 5494 │ pc端_互动/互动/抽奖-制作 │ pc端_互动/互动/抽奖-制作 │
└──────┴──────────────────────────────┴──────────────────────────────┘
- 支持用户自定义函数,UDF函数可以用任意编程语言编写。参考 https://chowdera.com/2021/10/20211025180833984r.html
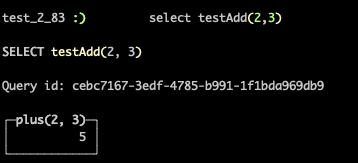
创建UDF函数1
CREATE FUNCTION testAdd AS (a, b) -> (a + b )
使用UDF函数
- 允许预定义的外部数据源连接。这可以避免在使用外部数据源时指定凭据或地址,而是可以用名称来引用它们。
- 将带有SCHEMATA、TABLES、VIEWS和COLUMNS视图的INFORMATION_SCHEMA数据库添加到系统数据库的相应表中。
- 支持EXISTS (subquery).
- 记录审核会话日志。将所有成功和失败的登录和注销事件记录到新系统。
- 支持多维余弦距离和欧氏距离函数;L1,L2,Lp,临汾距离和规范。元组上的标量积和元组上的各种算术运算符。
- 增加对输入输出和来自输入文件的压缩和解压缩的支持(带有自动检测或附加可选参数)。
- 通过HTTP OPTIONS请求添加CORS(跨来源资源共享)支持。这意味着,现在Grafana将可以处理无服务器的请求,而不会产生任何问题。
- JOIN ON的查询现在支持析取(或)
- 增加tokens函数,允许使用非字母数字ASCII字符作为分隔符将字符串拆分为标记。增加了ngrams函数,它可以从文本中提取ngram。
- 为Unicode规范化添加函数,normalizeUTF8NFC, normalizeUTF8NFD, normalizeUTF8NFKC, normalizeUTF8NFKD
- 使用FileLog表引擎在ClickHouse中流式使用应用程序日志文件。它就像kafka或RabbitMQ引擎,但只用于本地文件系统中的追加和循环日志。
- 增加CapnProto 输出格式,重构了CapnProto 输入格式。
- 允许以二进制字面量在查询语句中输入数字,比如 SELECT 0b001。
- 增加hashed_array 字典类型,当操作拥有多个属性的字典,用它比较节省内存。
- 增加JSONExtractKeys 函数。
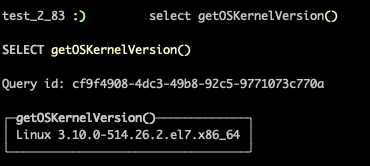
- 增加getOSKernelVersion 函数,它以字符串的形式返回操作系统内核的版本号。
- 增加MD4 和SHA384 函数。MD4是一个过时且不安全的哈希函数,它只能在极少数情况下使用,即MD4已经在某些遗留系统中使用,并且您需要获得完全相同的结果。
- 通过将配置文件中的hsts_max_age设置为正数,可以为Clickhouse HTTP服务器启用HSTS。
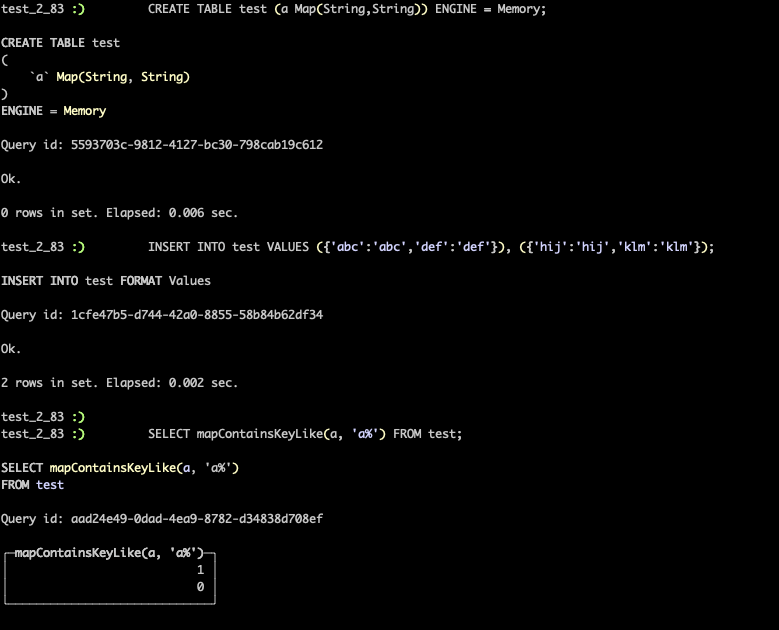
- 新函数mapContainsKeyLike获取与简单正则表达式匹配的键的映射。新函数mapExtractKeyLike获取只保留与指定模式匹配的元素的map。
实现了ALTER TABLE x MODIFY COMMENT语法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29:) ALTER TABLE test MODIFY COMMENT 'this is table comment!'
ALTER TABLE test
MODIFY COMMENT 'this is table comment!'
Query id: ebe5aa1b-5b38-4386-a800-7152082d8ef7
Ok.
0 rows in set. Elapsed: 0.006 sec.
:)show create table test;
SHOW CREATE TABLE test
Query id: b7c9d813-ee5f-4eab-9868-9cb68ba39535
┌─statement─────────────────────────────────────────────────────────────────────────────────────────────┐
│ CREATE TABLE default.test
(
`a` Map(String, String)
)
ENGINE = Memory
COMMENT 'this is table comment!' │
└───────────────────────────────────────────────────────────────────────────────────────────────────────┘
1 rows in set. Elapsed: 0.001 sec.增加添加ClickHouse中缺少但可通过H3 api获得的H3检测功能: https://h3geo.org/docs/api/inspection.
- 允许在Replicated数据库上执行非复制的ALTER TABLE FETCH和 ATTACH操作。
- 增加一个配置项output_format_csv_null_representation , 他和output_format_tsv_null_representation 一样,只是输出为CSV格式。
- 增加了一个函数,它以以秒为单位返回当前zk的正常运行时间。
- 实现了h3ToGeoBoundary 函数。
- 增加一个聚合函数exponentialMovingAverage ,可以被当成窗口函数使用。
- 允许将在表的DESCRIBE 查询结果中输出subcolumns的信息(通过设置describe_include_subcolumns来启用这个功能)。
- Executable, ExecutablePool 增加了send_chunk_header选项。
- tokenbf_v1 和 ngram 支持以FixedString类型为key的Map。这样在根据map key进行过滤的查询中可以跳过大量的无关的数据。通过sql CREATE TABLE map_tokenbf ( row_id UInt32, map Map(String, String), INDEX map_tokenbf map TYPE ngrambf_v1(4,256,2,0) GRANULARITY 1 ) Engine=MergeTree() Order by id 创建的表,select * from map_tokebf where map[‘K’]=’V’ 将跳过不包含A的部分。当然,这种方式查询会跳过多少数据,主要取决于granularity 和 index_granularity 的设置。
- 可以从server端发送profile事件到客户端,引入了新的packet类型ProfileEvents。
- 支持固定字符串和字符串数据类型的移位操作。
- 支持在MaterializedPostgreSQL中动态增加或删除来自PostgreSQL的复制表。
- 增加accurateCastOrDefault(x, T)函数
增加了 toUUIDOrDefault, toUInt8/16/32/64/256OrDefault, toInt8/16/32/64/128/256OrDefault 函数,还可以为这些函数指定一个非空默认值,当解析失败的时候会用到。
性能提升
现在url函数可以并行处理多个函数。
- 对于外部数据库(比如Mysql)使用IS NULL/IS NOT NULL 的时候支持下推。对于外部数据库(比如Mysql)会将isNull/isNotNull 转为IS NULL/IS NOT NULL。
在使用多个磁盘的情况下,可以加快数据加载过程。
提升
在无需重启服务的情况下,用户可以修改日志级别。
- SQL UDF多项优化,UDF函数现在支持CLUSTER模式,例如CREATE FUNCTION test_function ON CLUSTER ‘cluster’ AS x -> x + 1; 支持CREATE OR REPLACE, CREATE IF NOT EXISTS 语法,支持DROP IF EXISTS语法,例如DROP FUNCTION IF EXISTS test_function。支持lambda表达式,例如CREATE FUNCTION lambda_function AS x -> arrayMap(element -> element * 2, x); 支持clickhouse-local 模式。
在集群模式下使用使用UDF函数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41hadoop106 :) CREATE FUNCTION test_func1 ON CLUSTER 'bigdata2' AS x -> x + 1;
CREATE FUNCTION test_func1 ON CLUSTER bigdata2 AS x -> (x + 1)
Query id: 7559b244-cca0-4b78-a093-2373f3b899eb
┌─host────────────────┬──port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐
│ hadoop105 │ 10001 │ 0 │ │ 2 │ 1 │
│ hadoop104 │ 10001 │ 0 │ │ 1 │ 1 │
└─────────────────────┴───────┴────────┴───────┴─────────────────────┴──────────────────┘
┌─host────────────────┬──port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐
│ hadoop106 │ 10001 │ 0 │ │ 0 │ 0 │
└─────────────────────┴───────┴────────┴───────┴─────────────────────┴──────────────────┘
3 rows in set. Elapsed: 0.414 sec.
hadoop106 :) CREATE DATABASE IF NOT EXISTS dist_db ON CLUSTER bigdata2;
CREATE DATABASE IF NOT EXISTS dist_db ON CLUSTER bigdata2
Query id: 4bcbbfdc-f38f-437c-987b-d19f84d5e22f
┌─host────────────────┬──port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐
│ hadoop105 │ 10001 │ 0 │ │ 2 │ 0 │
│ hadoop106 │ 10001 │ 0 │ │ 1 │ 0 │
│ hadoop104 │ 10001 │ 0 │ │ 0 │ 0 │
└─────────────────────┴───────┴────────┴───────┴─────────────────────┴──────────────────┘
3 rows in set. Elapsed: 0.112 sec.
hadoop106 :) select test_func1(5);
SELECT test_func1(5)
Query id: 03a1e080-adb0-4d22-9192-1d40cc61e838
┌─plus(5, 1)─┐
│ 6 │
└────────────┘
1 rows in set. Elapsed: 0.001 sec.
除了YYYY-MM-DD之外,还允许将YYYYMMDD文本格式的数据解析为日期类型。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23test_2_83 :)select toDate('20160615')
SELECT toDate('20160615')
Query id: ba8234c1-557c-4d01-8022-0c2bed50804e
┌─toDate('20160615')─┐
│ 2016-06-15 │
└────────────────────┘
1 rows in set. Elapsed: 0.002 sec.
test_2_83 :)select toDate('2016-06-15')
SELECT toDate('2016-06-15')
Query id: 6ae8c0b6-29fd-469c-816b-de372a4a2835
┌─toDate('2016-06-15')─┐
│ 2016-06-15 │
└──────────────────────┘
1 rows in set. Elapsed: 0.001 sec.Web UI:在表格中呈现条。
- 用户可以在创建词典的时候使用备注:CREATE DICTIONARY … COMMENT ‘vaue’ … 用户在CREATE DATABASE 语句中为数据库设置备注。
- 可以用JSONExtractString将非字符串元素抽取出来,转换为string。
- 现在clickhouse-client 支持本地多行编辑。
- 跟踪内存峰值。
- 在服务运行时调整max_concurrent_queries 设置。(无需重启)
has函数,增加对Map 数据类型的支持。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27test_2_83 :)select * from test;
SELECT *
FROM test
Query id: ecb4e165-14e7-44c8-ba73-33da676d95ec
┌─a─────────────────────────┐
│ {'abc':'abc','def':'def'} │
│ {'hij':'hij','klm':'klm'} │
└───────────────────────────┘
2 rows in set. Elapsed: 0.002 sec.
test_2_83 :) select has(a,'def') from test;
SELECT has(a, 'def')
FROM test
Query id: 2fa4a7fc-069a-4155-8b00-28b7d1cb4c23
┌─has(a, 'def')─┐
│ 1 │
│ 0 │
└───────────────┘
2 rows in set. Elapsed: 0.017 sec.在CREATE … AS SELECT 语句中可以进行一些设置,比如 max_memory_usage 。