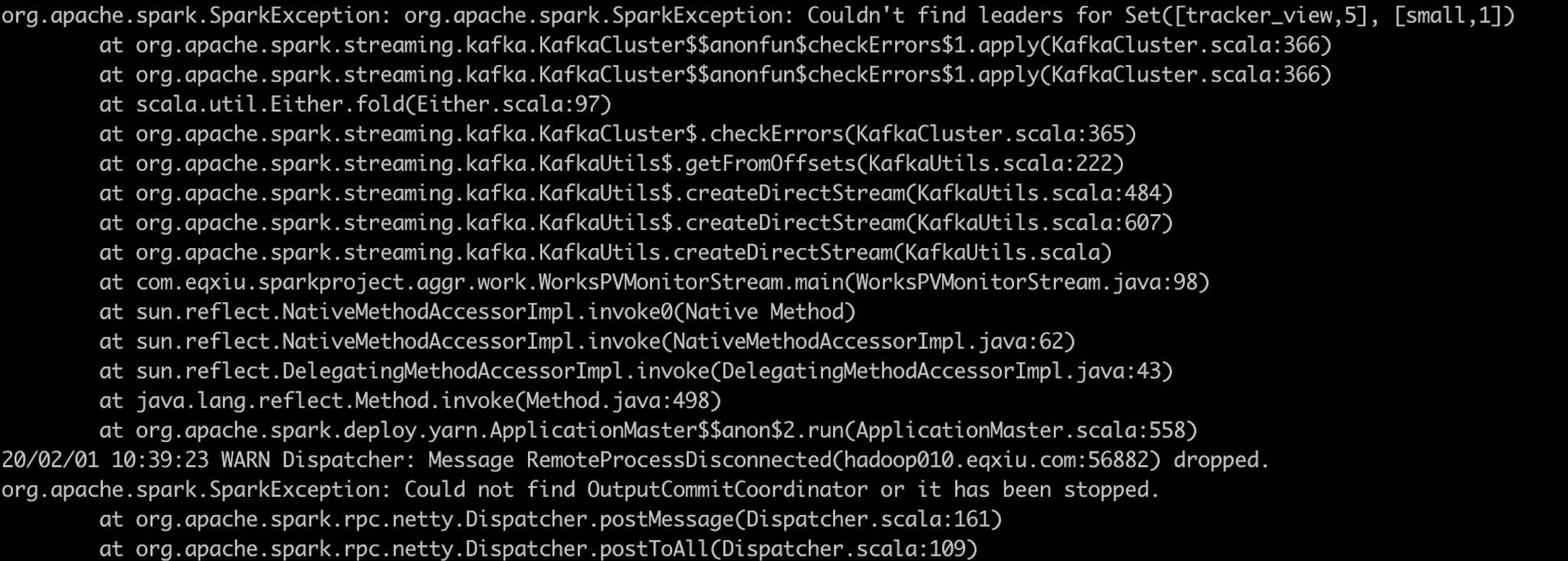
一般可能是broker挂掉了,通过kafka manager 查看是哪个broker挂掉了,或出问题了。
然后将对应的broker重新启动。
一般建议将topic的副本数设置为2或3.
一般可能是broker挂掉了,通过kafka manager 查看是哪个broker挂掉了,或出问题了。
然后将对应的broker重新启动。
一般建议将topic的副本数设置为2或3.
不能使用普通的drop database xxx命令,而要使用如下命令:1
DETACH DATABASE your_database_name
之后删除磁盘上基于mysql引擎的数据库的元信息:
1 | ~ rm -rf metadata/your_database_name |
下列语句在Hive命令行可以执行,但是在hue上好像不可以。
1 | hive> SET hive.exec.dynamic.partition = true; // 开启动态分区,默认是false |
https://blog.csdn.net/qq_26442553/article/details/80382174
http://shzhangji.com/cnblogs/2014/04/07/hive-small-files/
Concerning : The DataNode has 643,805 blocks. Warning threshold: 500,000 block(s).
可能是/tmp/logs 目录下的日志文件太多了
https://blog.csdn.net/b_x_p/article/details/78534423
如果配置了机器A免密码登录B,登录的时候还是需要密码,那么很有可能是B禁止了root登录。
在B上查看配置文件 /etc/ssh/sshd_config
1 | #禁用root账户登录,如果是用root用户登录请开启 |
将PermitRootLogin配置改成yes就可以了。
修改完,记得重启一下ssh的服务:1
2
3/bin/systemctl restart sshd.service
或者
service sshd restart
之前写了一个自动化登录的脚本,最近运维升级了堡垒机,导致这段时间无法登录,经过摸索排查,发现需要把每个send后的\n换成\r,然后又可以愉快的玩耍了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66#!/usr/bin/expect
set user hohode
set host jump.hohode.com
set password xxxxx
spawn ssh -i /Users/hohode/Documents/company/keys/online/hohode-jumpserver.pem $user@$host
expect "*Opt>*"
if { $argc == 1 } {
set seq [lindex $argv 0]
}
if { $seq == "nck" } {
send "hadoop019\r"
expect "jump@hadoop*"
send "sudo su -\r"
send "ssh 190.0.2.129\r"
send "cd /data/\r"
} elseif { $seq == "test" } {
send "190.0.2.73\r"
expect "jump@*"
send "sudo su -\r"
} elseif { $seq == "app001" || $seq == "app002" || $seq == "logserver001" || $seq == "logserver002" || $seq == "logserver003" } {
send "$seq \r"
expect "jump*"
send "sudo su -\r"
if { $seq == "app001" || $seq == "app002" } {
send "cd /data/work/pre_tracker/\r"
}
if { $seq == "logserver001" || $seq == "logserver002" || $seq == "logserver003" } {
send "cd /data/work/\r"
}
} elseif { $seq != "lll" } {
if { $seq == 1 || $seq == 2 || $seq == 6 } {
send "hadoop00$seq\r"
}
if { $seq == 19 } {
send "hadoop0$seq\r"
} else {
send "$seq\r"
}
expect "jump@*"
send "sudo su -\r"
if { $seq == 1 || $seq == 2 || $seq == 19 } {
expect "*root@hadoop*"
send "su - hdfs\r"
if { $seq == 1 } {
expect "*hdfs@hadoop*"
send "cd shell/new/\r"
} elseif { $seq == 2 } {
expect "*hdfs@hadoop*"
send "cd /data/work/shell/\r"
} elseif { $seq == 19 } {
expect "*hdfs@hadoop*"
send "cd shell/\r"
}
}
}
interact
expect eof
三个小实验:1.搭桥 2.造塔 3. 听说绘图
遇到一个项目或一件事情,拿到之后首先要考虑以下几项:
项目经理最好不要参与项目的实际开发。项目经理应该去把控项目时间,思考解决实现项目的最优方案,学习借鉴他人或现有的经验,从而青出于蓝而胜于蓝。
在做的过程中,全力以赴的去做,如果还达不到目标或没有结果,可以申请延长时间或者改变目标,或者其他的办法都可以。
1 | function printTitle(el) { |
制定一个printTitle方法,调用下面的代码就行了1
2
beginObserve('[tracking_id|="search"],[tracking_id|="re"]',printTitle);
一 安装Apache
1.安装apache1
yum -y install httpd
2.安装apache扩展1
yum -y install httpd-manual mod_ssl mod_perl mod_auth_mysql
3.启动apache1
2
3
4
5
6
7service httpd start
(centos 7 请使用下面命令)
systemctl start httpd.service #启动apache
systemctl stop httpd.service #停止
systemctl restart httpd.service #重启
systemctl enable httpd.service #设置开机自启动
设置行数据的过期时间为2分钟,每60秒合并一次数据。1
CREATE TABLE test.ttlt ( d DateTime, a Int ) ENGINE = MergeTree PARTITION BY toYYYYMM(d) ORDER BY d TTL d + INTERVAL 2 minute SETTINGS merge_with_ttl_timeout= 60
按照时长30分钟切割session1
SELECT u_i,sequenceCount1('(?1).*(?2)(?t>1800000)')(time, 1=1 ,1=1)+1 as cc from tracker_log group by u_i;