1 手机上打开开发者模式
每个品牌开启开发者模式的方式可能不同。以华为手机为例:
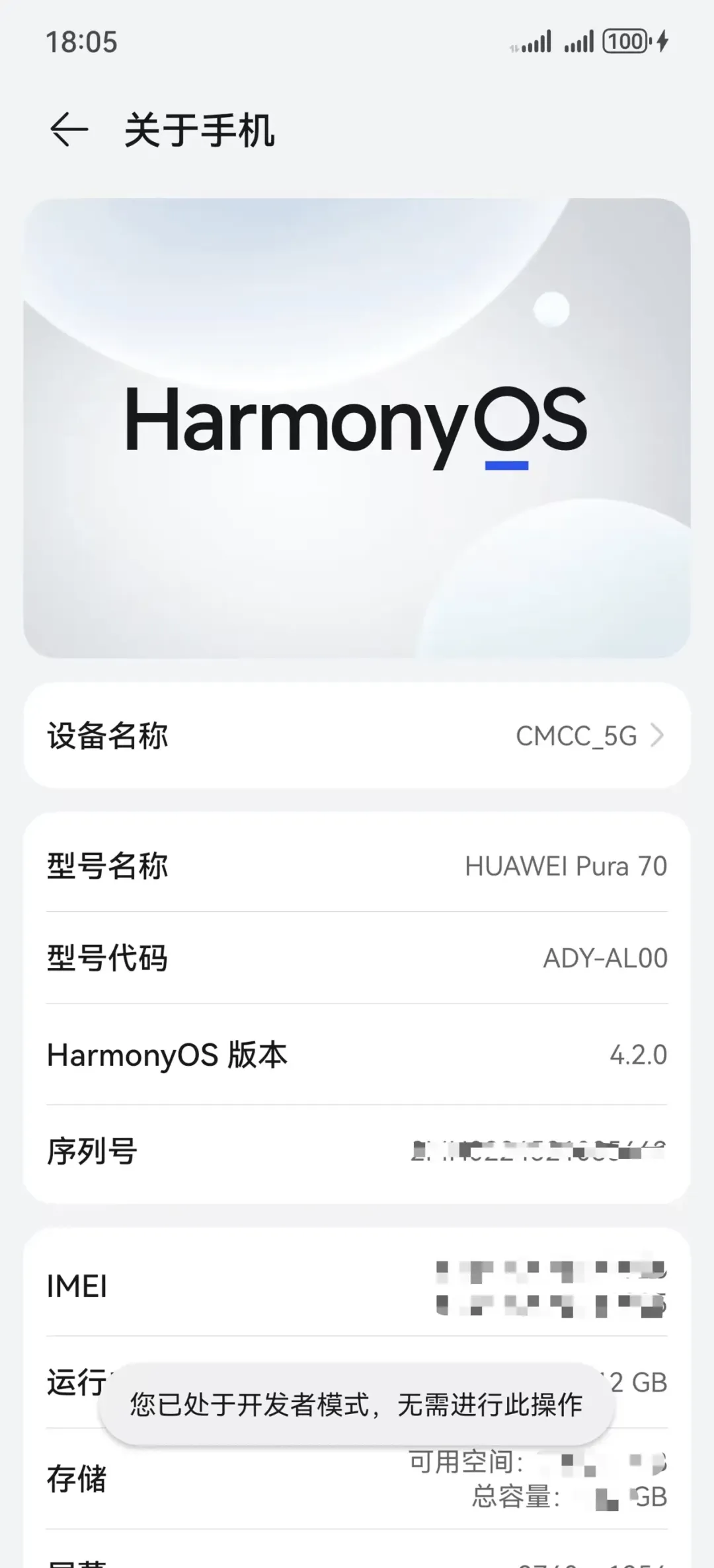
打开手机,进入“设置”页面,搜索“关于手机”选项。
快速点击“HarmonyOS版本”的项目多次,直到提示“您正处于开发者模式!”或者“您已处于开发者模式,无需进行此操作”,即表示您已经打开开发者选项,然后退出该页面。
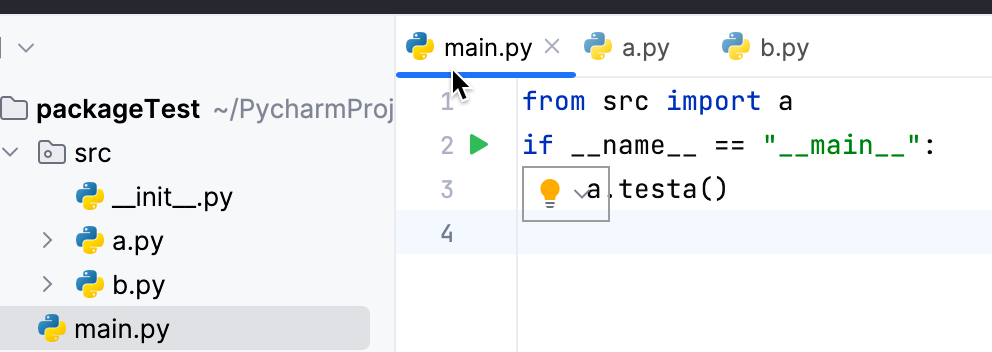
在目录下建立init.py文件,
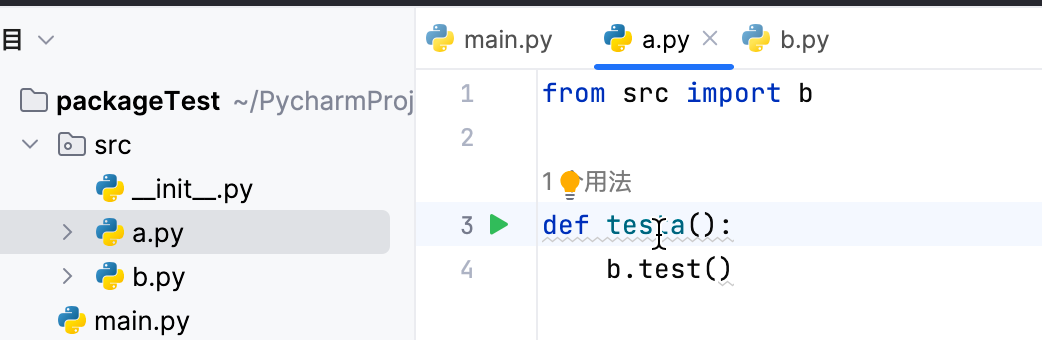
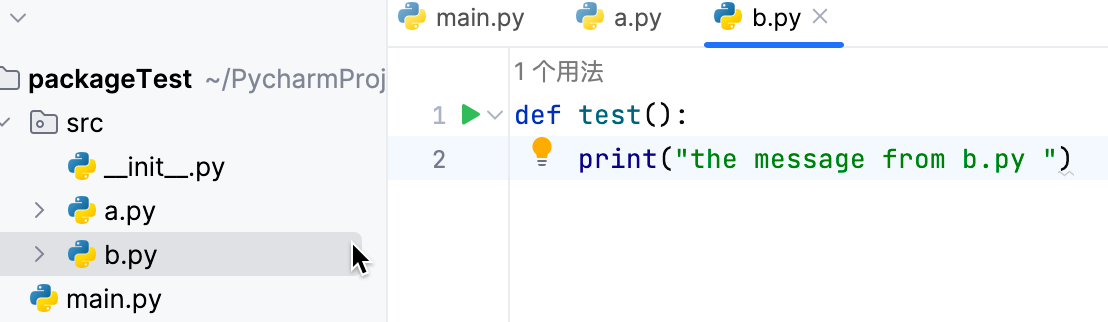
任何Python文件在引用其他py文件的时候,包含引用同级的py文件,都使用完整包名。比如
父元素设置为相对定位position:relative,子元素使用如下代码设置:1
2
3
4position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
1 | <html> |
根据 performance.navigation.type判断
https://www.zhihu.com/question/29036668
0表示从链接进去,1表示刷新
根据window.name判断
https://www.zhihu.com/question/29036668
1 | window.onload = function() { |
Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.
1 | $ hexo new "My New Post" |
More info: Writing
1 | $ hexo server |
More info: Server
1 | $ hexo generate |
More info: Generating
1 | $ hexo deploy |
More info: Deployment
为什么很多编程语言中数组都从0开始编号:
从 1 开始编号,每次随机访问数组元素都多了一次减法运算,对于 CPU 来说,就是多了一次减法指令。
数组作为非常基础的数据结构,通过下标随机访问数组元素又是其非常基础的编程操作,效率的优化就要尽可能做到极致。所以为了减少一次减法操作,数组选择了从 0 开始编号,而不是从 1 开始。
说数组起始编号非 0 开始不可。所以我觉得最主要的原因可能是历史原因。
C 语言设计者用 0 开始计数数组下标,之后的 Java、JavaScript 等高级语言都效仿了 C 语言,或者说,为了在一定程度上减少 C 语言程序员学习 Java 的学习成本,因此继续沿用了从 0 开始计数的习惯。实际上,很多语言中数组也并不是从 0 开始计数的,比如 Matlab。甚至还有一些语言支持负数下标,比如 Python。
JVM标记清除算法:
大多数主流虚拟机采用可达性分析算法来判断对象是否存活,在标记阶段,会遍历所有 GC ROOTS,将所有 GC ROOTS 可达的对象标记为存活。只有当标记工作完成后,清理工作才会开始。
不足:1.效率问题。标记和清理效率都不高,但是当知道只有少量垃圾产生时会很高效。2.空间问题。会产生不连续的内存空间碎片。
参考 https://www.51cto.com/article/626708.html
1 | docker pull mysql/mysql-server:latest |
通过docker镜像的方式启动Cannal-Server还有点问题,下边通过下载 canal-canal.deployer-1.1.7-SNAPSHOT.tar.gz ,然后通过命令行的方式启动
目前7.0以上版本跨集群备份的方式有很多,例如elasticsearch-dump,reindex,snapshot,logstash。
| 方案 | elasticsearch-dump | reindex | snapshot | logstash |
|---|---|---|---|---|
| 基本原理 | 逻辑备份,类似mysqldump将数据一条一条导出后再执行导入 | reindex 是 Elasticsearch 提供的一个 API 接口,可以把数据从一个集群迁移到另外一个集群 | 从源集群通过Snapshot API 创建数据快照,然后在目标集群中进行恢复 | 从一个集群中读取数据然后写入到另一个集群 |
| 网络要求 | 集群间互导需要网络互通,先导出文件再通过文件导入集群则不需要网络互通 | 网络需要互通 | 无网络互通要求 | 网络需要互通 |
| 迁移速度 | 慢 | 快 | 快 | 一般 |
| 适合场景 | 适用于数据量小的场景 | 适用于数据量大,在线迁移数据的场景 | 适用于数据量大,接受离线数据迁移的场景 | 适用于数据量一般,近实时数据传输 |
| 配置复杂度 | 中等 | 简单 | 复杂 | 中等 |
修改了Flume的配置,然后需要将有过期配置的服务重启了一下,然后集群上有些服务就异常了。
首先yarn服务异常,2个ResourceManager (分别为hadoop101和hadoop102) 同时处于standby状态。然后根据stackoverflow上的解释,使用如下命令1
yarn resourcemanager -format-state-store
在hadoop101上以hdfs用户执行,过了1分钟,问题仍旧没有解决,2个ResourceManager仍然同时处于standby状态。
from https://docs.microsoft.com/zh-cn/azure/databricks/sql/language-manual/functions/parse_url
从 url 中提取一部分。
1 | parse_url(url, partToExtract [, key] ) |
partToExtract 必须是以下各项之一:
如果未找到请求的 partToExtract 或 key,则返回 NULL。
SQL
1 | SELECT parse_url('http://spark.apache.org/path?query=1', 'HOST'); |