修改了Flume的配置,然后需要将有过期配置的服务重启了一下,然后集群上有些服务就异常了。
Yarn服务异常: 2个ResourceManager同时处于standby状态
首先yarn服务异常,2个ResourceManager (分别为hadoop101和hadoop102) 同时处于standby状态。然后根据stackoverflow上的解释,使用如下命令1
yarn resourcemanager -format-state-store
在hadoop101上以hdfs用户执行,过了1分钟,问题仍旧没有解决,2个ResourceManager仍然同时处于standby状态。
然后在hadoop102上以hdfs用户执行上述命令,第一次又报错了,而后又执行了一次,这次成功执行了此命令。过了1分钟,yarn的状态改变了,变成了绿色,也就是正常状态,hadoop101处于standby状态,hadoop102处于active状态。
之所以知道上述命令可以起作用,是因为之前遇到过这样的问题,就是通过这种方式解决的。
zookeeper异常
这个时候zookeeper还是处于异常状态,异常描述为“Canary test failed to establish a connection or a client session to the ZooKeeper service”。
重启Hive和Hue
谷歌了一下,大概了解到是因为和zk的连接太多,所以会有此问题。
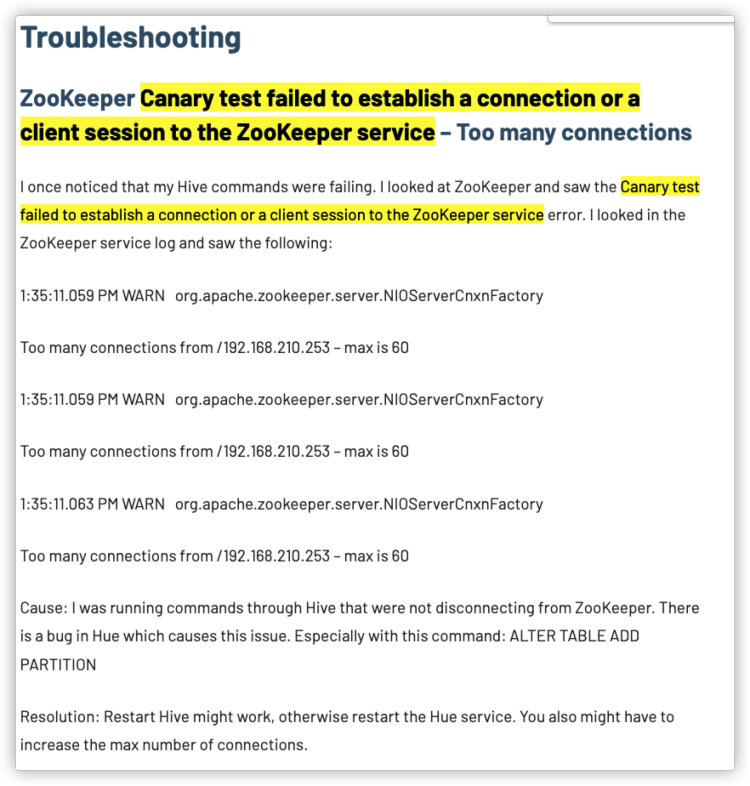
不过按照文章最下给的解决方法,分别重启了Hue和Hive,问题并没有得到解决。
查看一下服务器上zk的日志
然后想查看一下服务器上zk的日志,通过Clouder Manager 上Zookeeper的配置找到zk日志路径为/var/log/zookeeper。
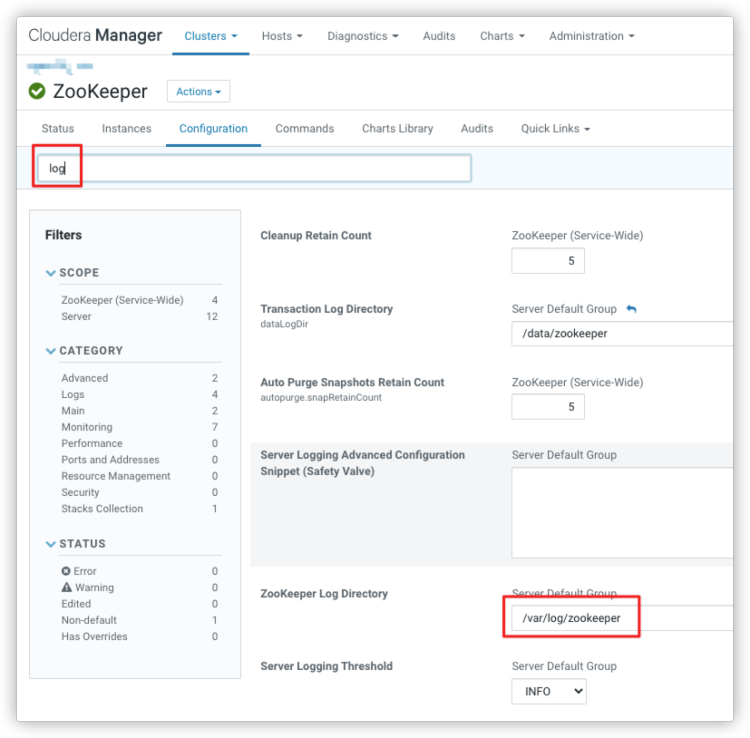
查看服务器上zk的日志,如下:1
2
3
4
5
6
7
8
9
10
11[hdfs@hadoop102 zookeeper]$ tail -f zookeeper-cmf-zookeeper-SERVER-hadoop102.eqxiu.com.log
2021-12-16 15:43:21,206 WARN org.apache.zookeeper.server.NIOServerCnxnFactory: Too many connections from /10.101.56.11 - max is 60
2021-12-16 15:44:13,675 WARN org.apache.zookeeper.server.NIOServerCnxnFactory: Too many connections from /10.101.56.11 - max is 60
2021-12-16 15:44:16,474 WARN org.apache.zookeeper.server.NIOServerCnxnFactory: Too many connections from /10.101.56.11 - max is 60
2021-12-16 15:44:19,184 WARN org.apache.zookeeper.server.NIOServerCnxnFactory: Too many connections from /10.101.56.11 - max is 60
2021-12-16 15:44:21,784 WARN org.apache.zookeeper.server.NIOServerCnxnFactory: Too many connections from /10.101.56.11 - max is 60
2021-12-16 15:44:24,026 WARN org.apache.zookeeper.server.NIOServerCnxnFactory: Too many connections from /10.101.56.11 - max is 60
2021-12-16 15:45:13,675 WARN org.apache.zookeeper.server.NIOServerCnxnFactory: Too many connections from /10.101.56.11 - max is 60
2021-12-16 15:45:16,446 WARN org.apache.zookeeper.server.NIOServerCnxnFactory: Too many connections from /10.101.56.11 - max is 60
2021-12-16 15:45:19,456 WARN org.apache.zookeeper.server.NIOServerCnxnFactory: Too many connections from /10.101.56.11 - max is 60
2021-12-16 15:45:22,816 WARN org.apache.zookeeper.server.NIOServerCnxnFactory: Too many connections from /10.101.56.11 - max is 60
从日志可以看出,日志解决为WARN,说明问题还不是很严重,“Too many connections from /10.101.56.11 - max is 60”说明来自10.101.56.11的连接太多了,然后根据这篇文章的介绍,在zk的各个服务器上分别执行如下命令1
sudo netstat -nap |grep 2181 | awk '{print $5}' | awk -F[:] '{print $1}' | sort | uniq -c
再次确认是10.101.56.1连接太多了,其连接数量是其他服务器的2倍,甚至更多。
从中找了一个端口 50850,然后去10.101.56.11服务器上执行如下密令1
2
3[root@hadoop101 ~]# lsof -i:50850
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 19727 yarn 384u IPv4 3014404568 0t0 TCP hadoop101:50850->hadoop102:eforward (ESTABLISHED)
发现这个服务来自于yarn,说明很可能时候这台服务器上的Yarn(ResourceManager)服务引起的,这就好办了,因为这台服务上的ResourceManager正好处于Standby状态,所以可以放心的重启。
于是就把此服务器上的ResourceManager先stop了,1分钟后观察zk的状态,现在已经处于变成了绿色,也就是正常状态了,如下图。
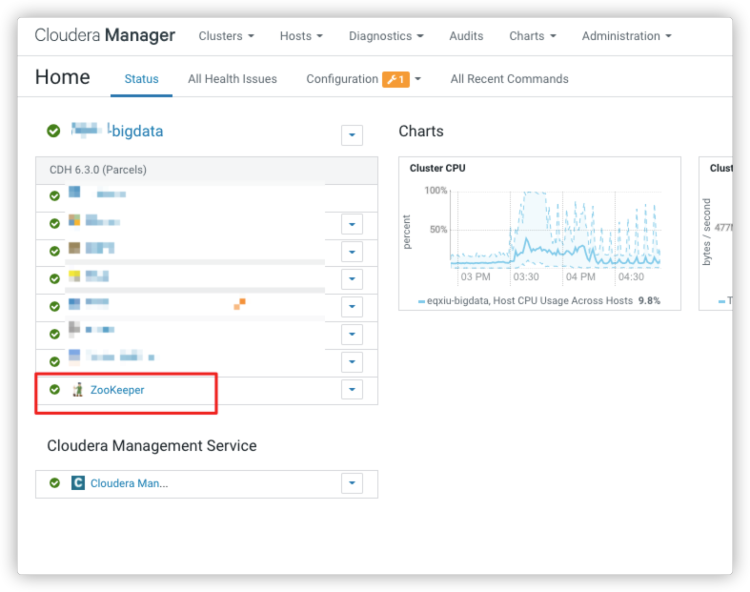
然后将ResourceManager再start就可以了。
整个集群处于正常状态了。