开源协议有多种,如MIT、BSD等,常见的有6种,关于这6种开源协议的区别,网上有一张图描述的是非常清楚的,这里贴一下
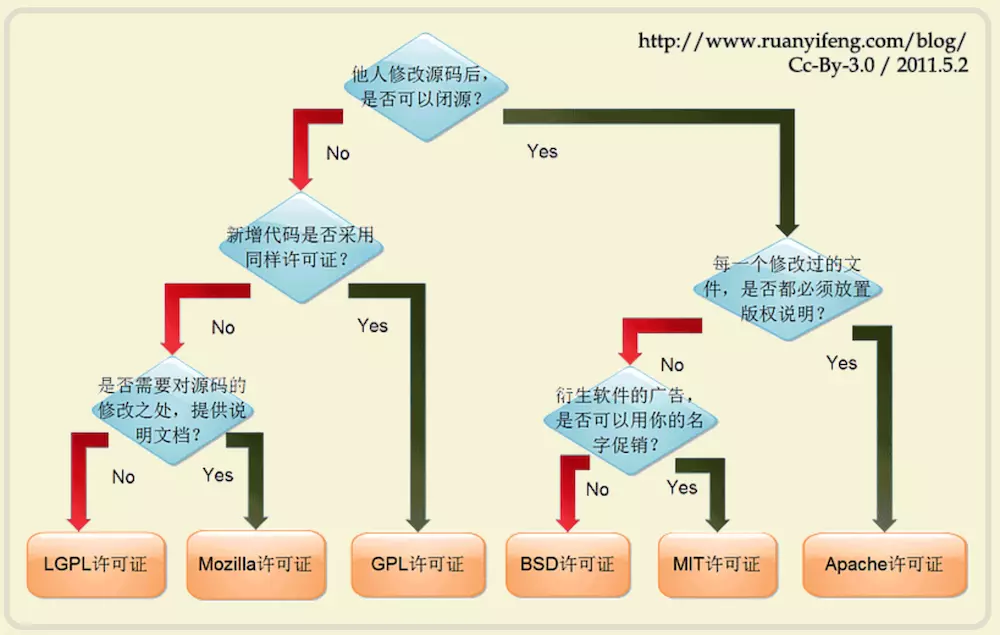
开源协议有多种,如MIT、BSD等,常见的有6种,关于这6种开源协议的区别,网上有一张图描述的是非常清楚的,这里贴一下
查看所有磁盘1
fdisk -l
查看现有磁盘信息1
df -hT
格式化磁盘
1 | mkfs.xfs /dev/vdd |
创建目录
mkdir /data2
挂载磁盘1
mount /dev/vdd /data2
查看原来kafka数据文件目录的大小1
du -sh /data/kafka/data
在新挂载的磁盘上创建目录1
mkdir -p /data2/kafka/data
为了减少kafka数据的大小,可以先动态改变kafka数据的保留时间,默认为7天,先改为12个小时1
kafka-topics --zookeeper node1:2181 -topic xxxx --alter --config retention.ms=86400000
等重启kafka之后,可以将此配置参数改过来
停掉这台机器上的kafka broker
将原来kafka数据拷贝到新的目录1
cp -r /data/kafka/data/* /data2/kafka/data/
对新目录的kafka数据授权1
chown -R kafka:kafka /data2/kafka/data
将原来目录中的kafka数据备份1
mv /data/kafka/data /data/kafka/data.bak
将这台机器上的kafka的数据目录(log.dirs)改为/data2/kafka/data
启动这台机器上的kafka broker
过3分钟,观察yarn上的任务,大部分已经恢复正常工作。
Windows用户在使用Excel处理数据文件时都不会关心文件的编码,因为Excel支持Windows上默认使用的简体中文编码GB2312。但是,使用MAC的用户就没有那么省心了,一不小心就会碰到中文乱码的问题。
在Mac上的Excel中为什么会出现中文乱码的情况呢?这是就需要了解一些文件编码的背景知识。
文件在计算内部采用的是二进制(0和1)的形式存放,那么给定一个0和1组成的串,计算机怎么知道这个串代表的是英文中的’a’还是中文里面的’好’?这时就需要用到文件的编码,不同的编码告诉了计算机怎么去识别文件的内容,例如GB2312编码告诉计算机’001’代表的是中文里面的’好’,而UTF8编码告诉计算机’001’代表的是英文里面的’a’(这个例子只是为了简述文件编码的作用,实际上的编码比这个复杂得多)。
由于UTF-8编码同时支持中文、还是日文、韩文、阿拉伯文在类的各种语言,所以它在Mac中被广泛使用,而目前Mac上的Excel在导入CSV文件时虽然给出了UTF8的选项,但是导入以后的中文还是乱码,这是因为它实际上是不支持UTF8编码方式导致的,至少对于Excel 2011 for Mac是这样。
那么怎么解决这个问题呢,方法很简单:将文件的编码方式由UTF8转为Excel支持的中文编码方式,Mac上的iconv工具专门就可以用来干这个事情。例如,在Excel给出的中文编码方式中有GB18030,那么我们可以通过Mac上的iconv工具将文件编码由UTF8转为GB18030。只需要在命令行中键入如下的命令:
1 | iconv -f UTF8 -t GB18030 源文件.csv >新文件.csv |
就可以将“源文件.csv”文件的编码方式由UTF8 变为GB18030并写入到“新文件.csv”文件中,在Excel中导入“新文件.csv”文件中的内容,我们会发现烦人的中文乱码消失的无影无踪了!
差点忘了最重要的一个问题,使用iconv的前提是我们知道文件的编码,那么Mac上怎么知道文件的编码呢?其实很容易啦,首先用Mac自带的编辑器vim打开文件,然后使用命令1
:set fileencoding
vim就会在屏幕的下方显示文件的编码。
下载
https://xclient.info/s/omni-plan.html#versions
记得打开是的时候需要密码
打开安全性设置
https://blog.csdn.net/CC1991_/article/details/78421108
OmmiPlanPro3.md
先声明一个mutable.HashMapString,Long个变量
var topicCountForIntervalMap = mutable.HashMapString,Long
使用如下语句,进行加减操作1
val t:Long = topicCountForIntervalMap.getOrElse(key,0) - TopicPartitionOffsetInfo.last.topicCountForIntervalMap.getOrElse(key,0)
得到如下错误1
2
3
4
5
6
7
8
9
10[ERROR] /xxxxx-java/src/main/scala/com/xxx/bigdata/kafka/monitor/TopicPartitionOffsetInfo.scala:86: error: overloaded method value - with alternatives:
[ERROR] (x: Long)Long <and>
[ERROR] (x: Int)Long <and>
[ERROR] (x: Char)Long <and>
[ERROR] (x: Short)Long <and>
[ERROR] (x: Byte)Long
[ERROR] cannot be applied to (AnyVal)
[ERROR] val t:Long = topicCountForIntervalMap.getOrElse(key,0L) - TopicPartitionOffsetInfo.last.topicCountForIntervalMap.getOrElse(key,0)
[ERROR] ^
[ERROR] one error found
解决办法,在使用getOrElse的使用一定要保证数据类型一致,改成如下的语句1
val t:Long = topicCountForIntervalMap.getOrElse(key,0L) - TopicPartitionOffsetInfo.last.topicCountForIntervalMap.getOrElse(key,0L)
就可以了
归并排序使用的就是分治思想。分治,顾名思义,就是分而治之,将一个大问题分解成小的子问题来解决。小的子问题解决了,大问题也就解决了。
分治算法一般都是用递归来实现的。分治是一种解决问题的处理思想,递归是一种编程技巧。
递归代码的编写技巧:分析得出递推公式,然后找到终止条件,最后将递推公式翻译成递归代码。
归并排序是一个稳定的排序算法。
第二,归并排序的时间复杂度是多少?
归并排序的执行效率与要排序的原始数组的有序程度无关,所以其时间复杂度是非常稳定的,不管是最好情况、最坏情况,还是平均情况,时间复杂度都是O(nlogn)。
第三,归并排序的空间复杂度是多少?
空间复杂度是O(n)。
快速排序的原理
快速排序并不是一个稳定的排序算法。
内容小结
归并排序和快速排序是两种稍微复杂的排序算法,它们用的都是分治的思想,代码都通过递归来实现,过程非常相似。理解归并排序的重点是理解递推公式和merge()合并函数。同理,理解快排的重点也是理解递推公式,还有partition()分区函数。
归并排序算法是一种在任何情况下时间复杂度都比较稳定的排序算法,这也使它存在致命的缺点,即归并排序不是原地排序算法,空间复杂度比较高,是O(n)。正因为此,它也没有快排应用广泛。
快速排序算法虽然最坏情况下的时间复杂度是O(n2),但是平均情况下时间复杂度都是O(nlogn)。不仅如此,快速排序算法时间复杂度退化到O(n2)的概率非常小,我们可以通过合理地选择pivot来避免这种情况。
展示分区操作的那个图不是很理解
现在你有10个接口访问日志文件,每个日志文件大小约300MB,每个文件里的日志都是按照时间戳从小到大排序的。你希望将这10个较小的日志文件,合并为1个日志文件,合并之后的日志仍然按照时间戳从小到大排列。如果处理上述排序任务的机器内存只有1GB,你有什么好的解决思路,能“快速”地将这10个日志文件合并吗?
我感觉评论中的高手说的很对。我就简单的记录一下。
先构建十条io流,分别指向十个文件,每条io流读取对应文件的第一条数据,然后比较时间戳,选择出时间戳最小的那条数据,将其写入一个新的文件,然后指向该时间戳的io流读取下一行数据,然后继续刚才的操作,比较选出最小的时间戳数据,写入新文件,io流读取下一行数据,以此类推,完成文件的合并, 这种处理方式,日志文件有n个数据就要比较n次,每次比较选出一条数据来写入,时间复杂度是O(n),空间复杂度是O(1),几乎不占用内存,这是我想出的认为最好的操作了。
消息系统的全局有序性的实现。
HQ Trivia 的员工发动政变要换掉 ceo,结果失败了
阅读原文
这是一则旧闻。两年前火了一把的有奖直播答题 app HQ Trivia 最近不火了;公司俩创始人,一个去年嗑药而死,一个是现在的 ceo;ceo刚刚平息了一场内部叛乱,局面控制下来了。
30 岁的 Game Boy 获得重生
阅读原文
Game Boy 于 1989 年 4 月份推出,最近刚过完 30 岁生日。有不少人改装/改进 Game Boy,比如加个摄像头,打印机,接上电吉他等。
写一个 Game Boy 或80/90年代的游戏机的模拟器,对于掌握计算机基础知识是很有帮助的。本科的时候有个同学在我们大二那年写了个任天堂红白机的模拟器。
睡眠质量比任何编程语言任何软件开发方法论都要重要
阅读原文
开发高质量的软件?先保证睡眠质量。这比什么编程语言,tdd,敏捷开发,什么最佳实践等都要重要。流水线工人都知道疲劳操作是很容易出事故的;那写软件呢?
如果软件只是用来分享你家的猫的照片,或者用来骗投资人的钱,那无所谓;如果软件是用来搞无人驾驶,医疗,建筑,航天等重要的事情,一定要严肃对待。
The Psychology of Startup Growth
阅读原文
很多人幻想“上线第一天,用户百万”,或者某个鸡贼伎俩可以瞬间增加几百万用户,这是不科学的。growth 是个过程,通常是漫长的过程,每个growth小伎俩只能增加一点,但尝试几千几万个以后,雪球就滚起来了。
Facebook 用了一年才达到一百万个用户。
Carta 101
阅读原文
2015年分享过这篇文章,那时候这家公司还叫做 eShare,后来改名 Carta;最近又重读了一遍,强烈推荐。公司不是家庭,而是职业运动队;每个员工必须早上8点半同时上班。
文中推荐的视频也强烈推荐一把:https://www.youtube.com/watch?v=ReSlJ5cq5D0 这是 Twilio 创始人 ceo 的演讲。要用软件的思维来解决问题;尽管很多人自称在“科技圈”工作,但思维还停留在19世纪体力劳动为主的时代。
将你的文件加入Python路径方法有很多种,以下我认为比较好的一种方式。
创建一个.pth文件,将目录列举出来,像这样:1
2# myapplication.pth
/Users/xiaowang/PycharmProjects/hohode/src/util
这个.pth文件需要放在某个Python的site-packages目录,通常位于/usr/local/lib/python3.3/site-packages 或者 ~/.local/lib/python3.3/sitepackages。比如我的文件路径为/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/myapplication.pth目录。
当解释器启动时,.pth文件里列举出来的存在于文件系统的目录将被添加到sys.path。
查看sys.path1
2
3
4
5
6
7
8
9
10Peace:site-packages hohode$ python3
Python 3.7.0 (v3.7.0:1bf9cc5093, Jun 26 2018, 23:26:24)
[Clang 6.0 (clang-600.0.57)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
> import sys
> sys.path
['', '/Library/Frameworks/Python.framework/Versions/3.7/lib/python37.zip', '/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7', '/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/lib-dynload', '/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages', '/Users/xiaowang/PycharmProjects/hohode/src/util']
> import wcommon
> wcommon.getLocalIp()
'222.21.126.112'
安装一个.pth文件可能需要管理员权限,如果它被添加到系统级的Python解释器。
from https://python3-cookbook.readthedocs.io/zh_CN/latest/c10/p09_add_directories_to_sys_path.html
Startup idea checklist
阅读原文
每个人都能凭空想出一堆的自认为很厉害的创业 idea。但哪个 idea 真的值得去做?可以把每个 idea 拿出来,回答文中的每个问题;回答完后,你还觉得你的 idea 很厉害吗?
在办公聊天软件里别说 “hello”
阅读原文
办公环境里,即时通讯其实并不即时,一般是异步的;发消息过来,可能过段时间才回。为了提高沟通效率,最好省去问候语,第一句话直接把问题、事情讲清楚,对方看到了就能直接回复。
Production ready code is much more than error handling
阅读原文
当代的软件大多数“线上服务”,必须24小时都能用的。production ready 不只是代码要写得好,要有一系列配套的流程、工具、实践来保证线上服务不挂掉、或者挂掉了后能尽快找出问题、尽快修复。
Great developers are raised, not hired
阅读原文
与其抱怨“很难招到明星级别的工程师”,不如在公司里创造好的环境,让自家的工程师成长为明星级别的工程师。
“如果培养成明星级别的工程师了,最后却被别的公司挖走了怎么办?” 所以你喜欢养着一群永远不成长、混饭吃、假装在工作的平庸工程师?
Windows 操作系统是用什么语言写的
阅读原文
微软的工程师的 Quora 回答:kernel 几乎是 C,越往上层 C++ 就多了起来。超过400万个源文件,超过 500GB。
为何科技公司这么喜欢招经济学家
阅读原文
经济学 PhD 的训练很适合当代互联网公司:数据驱动、发掘事物的因果关系、双边市场等。
Apple Plus - brand versus subscription
阅读原文
Apple 推出一系列 service,其品牌从逼格高、高冷,转向注重隐私、对家庭友好,试图成为科技圈中的迪士尼。所以没有广告,没有 Game of Thrones 这种儿童不宜的神剧。
Why Setting Ambitious Goals Backfires
阅读原文
公司里实行OKR机制、指定目标,最好的结果是完成70%,完成太多标明你野心不大,完成太少标明你太弱了。但制定这种明知道完不成的目标,往往会驱使员工追逐短期利益、压力太大、容易沮丧。
我们为何从 Heroku 迁移到 Google Kubernetes Engine
阅读原文
这笔账算得不错:公司最初几年用 Heroku,虽然不便宜,但也比招若干个全职员工做运维要便宜许多。
RethinkDB: why we failed
阅读原文
RethinkDB从2009年开始做,到2017年宣告创业失败,是MongoDB的竞争产品。RethinkDB技术做得不错,打磨了三年才正式推出,却远远输给了技术不咋地、但营销很牛逼的MongoDB(已上市)。